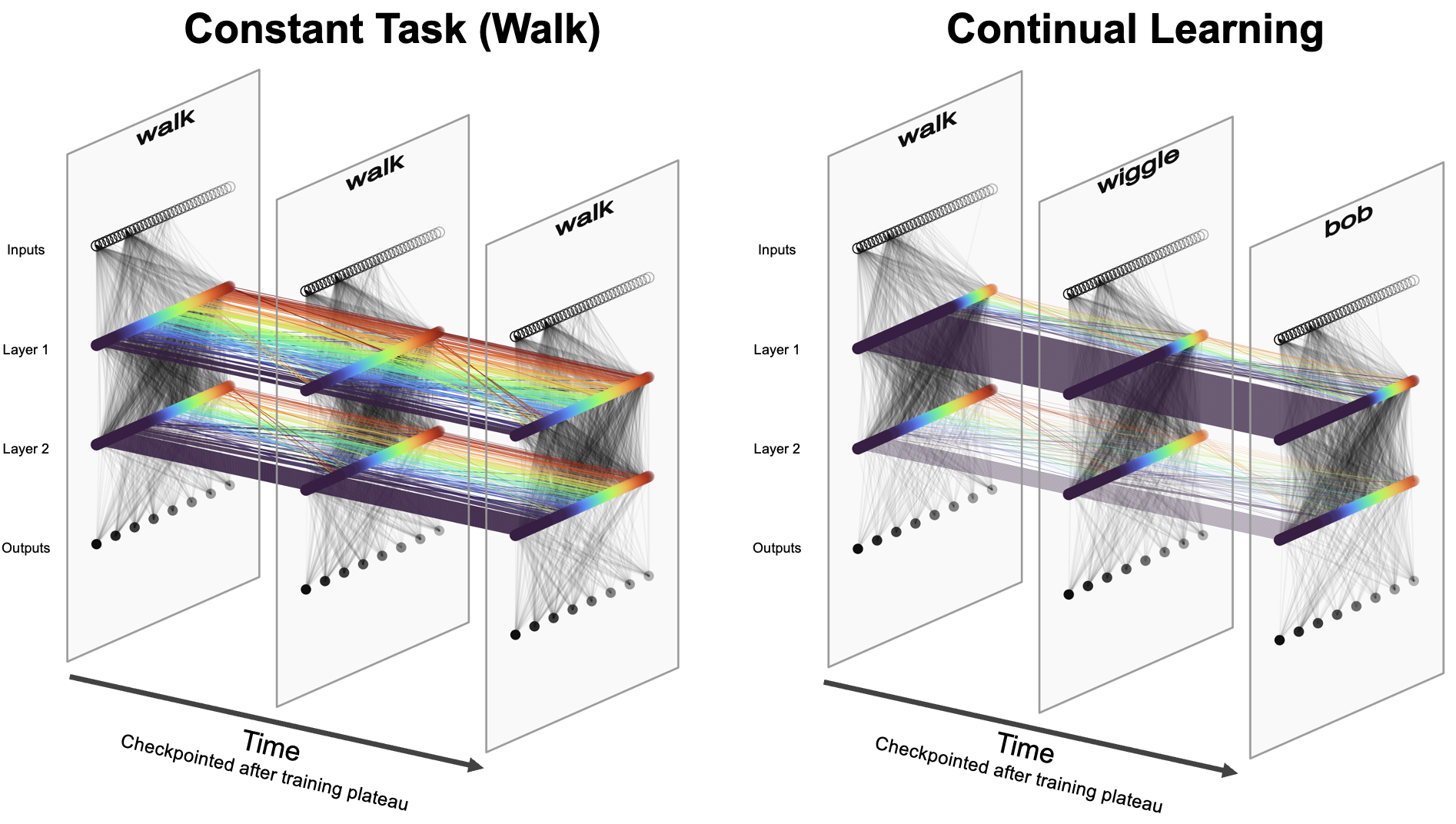
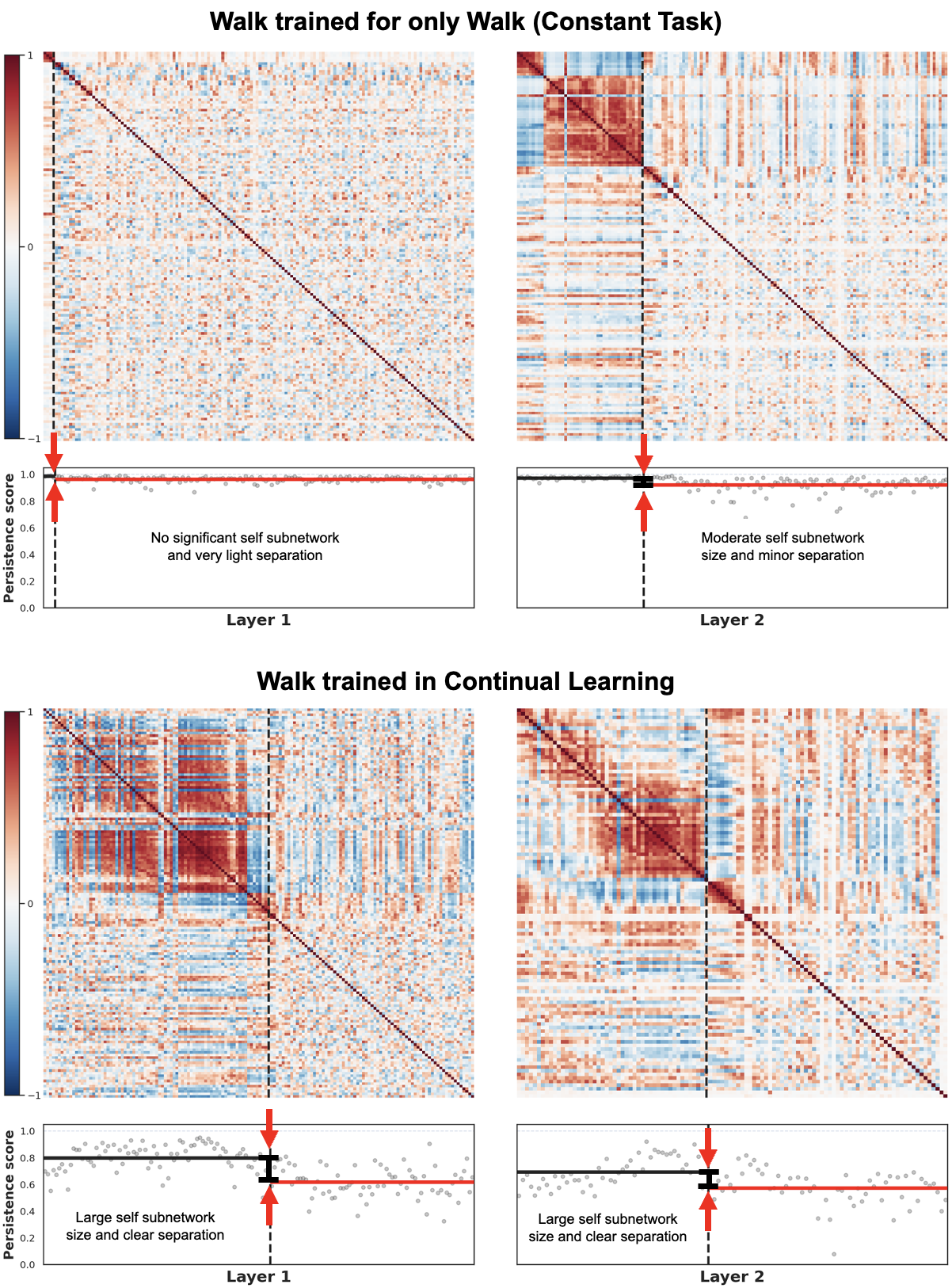
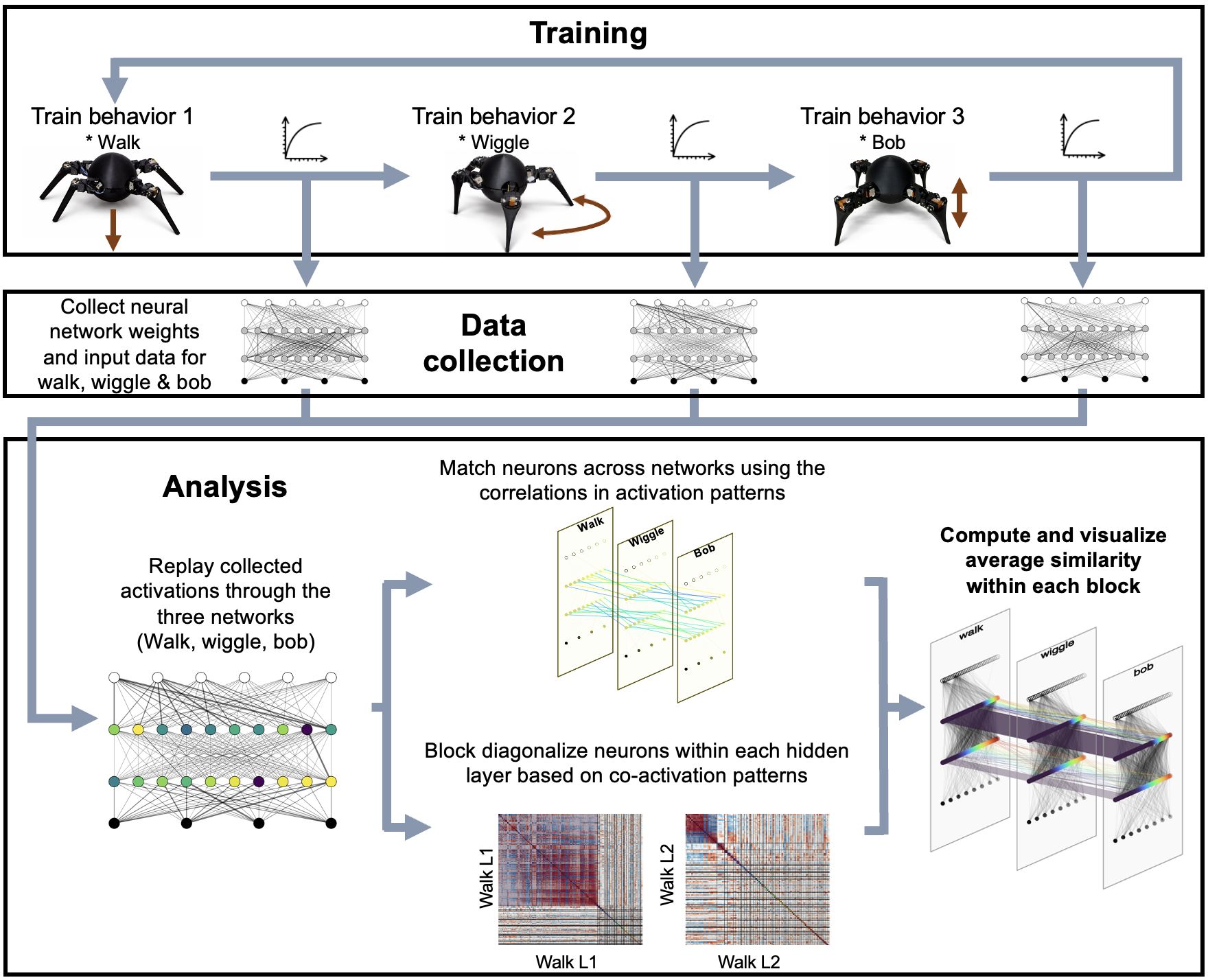
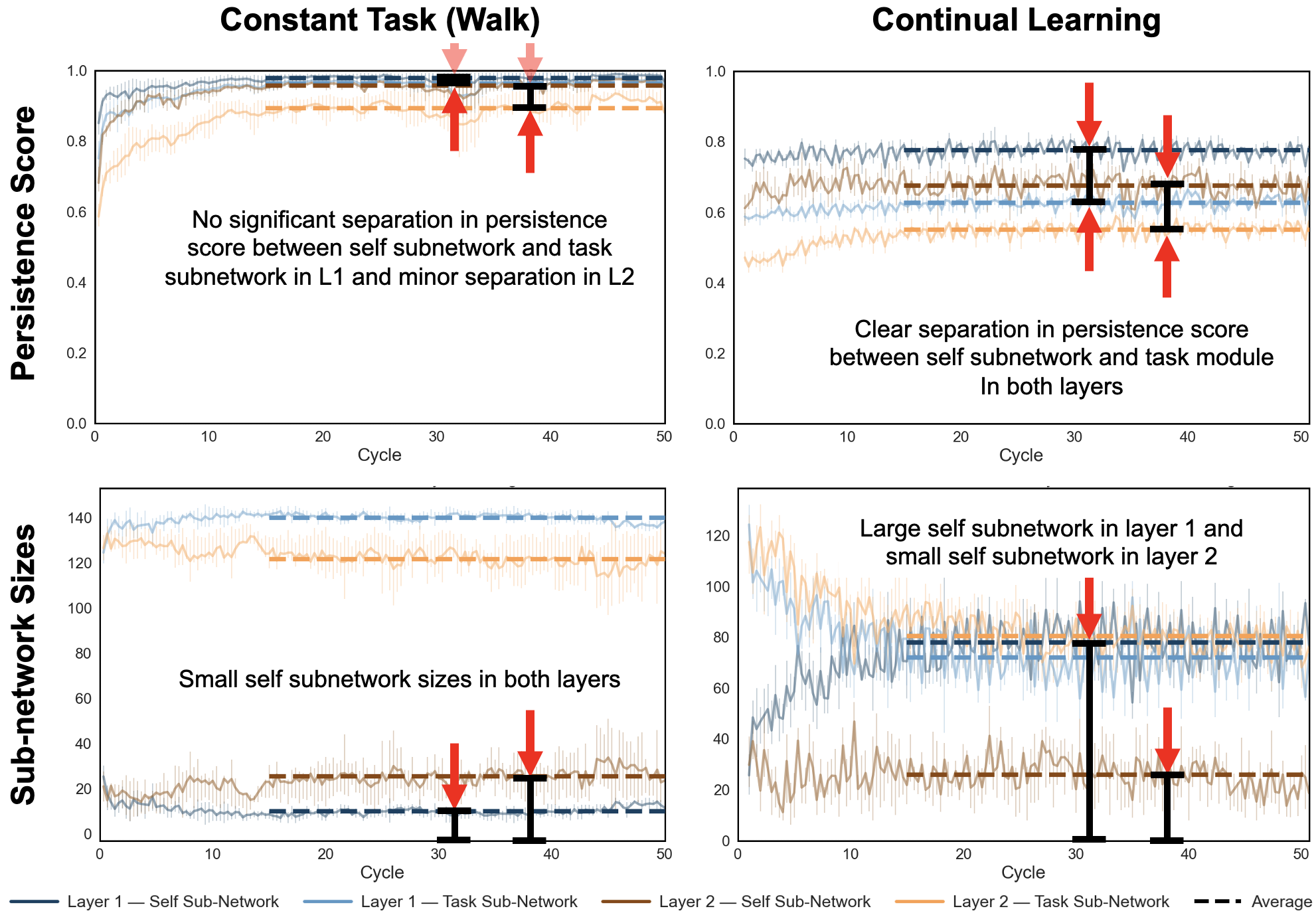
What, exactly, stays the same when a robot learns to do something new?
Humans do not relearn their bodies from scratch every time the goal changes. We may learn a new skill, adapt to a new environment, or recover from a mistake, but some internal sense of the body carries forward. This project asks whether something similar can emerge inside a learned robot controller.
In this work, we trained a single robot across multiple behaviors and then looked inside the neural policy to test whether a stable, reusable internal subnetwork emerged—something closer to a persistent sense of the robot’s own body than a one-off task controller.